A team of neuroscientists at the University of California San Francisco used brain signals recorded from epilepsy patients to program a computer to mimic natural speech, an advancement that could one day have a profound effect on the ability of certain patients to communicate. The results were published in the journal Nature.

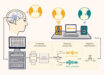
A brain-machine interface created Anumanchipalli et al can generate natural-sounding synthetic speech by using brain activity to control a virtual vocal tract. Image credit: University of California San Francisco.
Technology that translates brain activity into speech would be transformative for people who are unable to communicate as a result of neurological impairments.
Decoding speech from neural activity is challenging because speaking requires very precise and rapid control of vocal tract articulators.
University of California San Francisco’s Professor Edward Chang and colleagues designed a neural decoder that uses sound representations encoded in brain activity to synthesize audible speech.
“Speech is an amazing form of communication that has evolved over thousands of years to be very efficient. Many of us take for granted how easy it is to speak, which is why losing that ability can be so devastating,” Professor Chang said.
“For the first time, our study demonstrates that we can generate entire spoken sentences based on an individual’s brain activity.”
The research builds on a recent study in which the team described for the first time how the human brain’s speech centers choreograph the movements of the lips, jaw, tongue, and other vocal tract components to produce fluent speech.
From that work, the researchers realized that previous attempts to directly decode speech from brain activity might have met with limited success because these brain regions do not directly represent the acoustic properties of speech sounds, but rather the instructions needed to coordinate the movements of the mouth and throat during speech.
“The relationship between the movements of the vocal tract and the speech sounds that are produced is a complicated one,” said co-author Dr. Gopala Anumanchipalli, a speech scientist at the University of California San Francisco.
“We reasoned that if these speech centers in the brain are encoding movements rather than sounds, we should try to do the same in decoding those signals.”
In the study, the neuroscientists asked five volunteers being treated at the University of California San Francisco’s Epilepsy Center — patients with intact speech who had electrodes temporarily implanted in their brains to map the source of their seizures in preparation for neurosurgery — to read several hundred sentences aloud while the researchers recorded activity from a brain region known to be involved in language production.
Based on the audio recordings of participants’ voices, they used linguistic principles to reverse engineer the vocal tract movements needed to produce those sounds: pressing the lips together here, tightening vocal cords there, shifting the tip of the tongue to the roof of the mouth, then relaxing it, and so on.
This detailed mapping of sound to anatomy allowed the authors to create a realistic virtual vocal tract for each participant that could be controlled by their brain activity.
This comprised two ‘neural network’ machine learning algorithms: a decoder that transforms brain activity patterns produced during speech into movements of the virtual vocal tract, and a synthesizer that converts these vocal tract movements into a synthetic approximation of the participant’s voice.
The synthetic speech produced by these algorithms was significantly better than synthetic speech directly decoded from participants’ brain activity without the inclusion of simulations of the speakers’ vocal tracts.
The algorithms produced sentences that were understandable to hundreds of human listeners in crowdsourced transcription tests conducted on the Amazon Mechanical Turk platform.
As is the case with natural speech, the transcribers were more successful when they were given shorter lists of words to choose from, as would be the case with caregivers who are primed to the kinds of phrases or requests patients might utter.
The transcribers accurately identified 69% of synthesized words from lists of 25 alternatives and transcribed 43% of sentences with perfect accuracy.
With a more challenging 50 words to choose from, transcribers’ overall accuracy dropped to 47%, though they were still able to understand 21% of synthesized sentences perfectly.
“We still have a ways to go to perfectly mimic spoken language,” said co-authors Josh Chartier, a bioengineering graduate student at the University of California San Francisco.
“We’re quite good at synthesizing slower speech sounds like ‘sh’ and ‘z’ as well as maintaining the rhythms and intonations of speech and the speaker’s gender and identity, but some of the more abrupt sounds like ‘b’s and ‘p’s get a bit fuzzy.”
“Still, the levels of accuracy we produced here would be an amazing improvement in real-time communication compared to what’s currently available.”
The researchers are currently experimenting with higher-density electrode arrays and more advanced machine learning algorithms that they hope will improve the synthesized speech even further.
The next major test for the technology is to determine whether someone who can’t speak could learn to use the system without being able to train it on their own voice and to make it generalize to anything they wish to say.
_____
Gopala K. Anumanchipalli et al. 2019. Speech synthesis from neural decoding of spoken sentences. Nature 568: 493-498; doi: 10.1038/s41586-019-1119-1